
Wymyśliłem sobie dzisiaj automatycznego like'a na facebooka. Działanie: użytkownik klika w cokolwiek na stronie, a efektem kliknięcia jest dodanie posta na jego tablicy facebookowej (bez żadnego zezwalania na integrację itd...).
Użytkownik musi być zalogowany na facebooku, a dalej jest to już dość proste:
1. Umieszczamy na stronie przycisk facebookowy, który można wygenerować tutaj:
http://developers.facebook.com/docs/reference/plugins/like
2. Przycisk otaczamy divem i za pomocą jquery pozycjonujemy tak żeby gonił pod kursorem
Efekt widać tutaj: http://automat-facebook.programistawww.pl/example.php
Pozostaje ukryć button za pomocą CSS i opacity i oprogramować zdarzenie onclick...
Niestety nie wpadłem na pomysł jak wykryć zdarzenie onclick (jest ono wewnątrz ramki do której nie mamy dostępu), więc oprogramowałem zdarzenie onblur dla dokumentu, gdzie chowam diva z facebookiem.
Całość w działaniu tutaj:
http://automat-facebook.programistawww.pl/
kod tutaj:
Ma ktoś pomysł jak zweryfikować, czy user zlikeował naszą stronę??
środa, 29 grudnia 2010
czwartek, 9 grudnia 2010
CUFON Opera - nie działa, nie ładuje...
Odkryłem dzisiaj zabawne zachowanie znanego skryptu do specjalnych czcionek: CUFON. Jeżeli mamy w dokumencie podpięty jakikolwiek PUSTY arkusz stylów CSS, to skrypt po prostu nie działa w przeglądarce opera...Trochę tajemny dla mnie ten związek, ale tak jest - odkryte po wykasowaniu zawartości pliku CSS z pluginu do systemu socialengine, w celu napisania ich od nowa :)
wtorek, 21 września 2010
Brutto i netto na fakturach - ZAGADKA
Jestem w trakcie ciężkich bojów, w których bierze udział program Subiekt GT, mechanizm sklepu Magento, mój ukochany arkusz kalkulacyjny MS Excell oraz JA - PROGRAMISTA. Chodzi o import i synchronizację danych pomiędzy tymi delikwentami, co nawet zaczyna się udawać i jak tylko uda mi się zakończyć temat, tak, że nie będzie mi spędzał snu z powiek, to podzielę się częścią rozwiązań na blogu :) Ale nie o tym...
Dzisiaj zauważono, że w programie subiekt na fakturze w pozycji koszt wysyłki zamiast 16,00zł wchodzi kwota 15,99zł - wniosek: programista oszukuje na grosiki (jak kiedyś ponoć jedna Pani w sklepiku szkolnym). Na fakturę wchodzi pozycja z produktem z Subiekta, któremu wpisano cenę brutto 16zł, a subiekt sam wyliczył cenę netto (przy podatku VAT 22%) w kwocie: 13,11zł.
Co robi program importu?
Łączy się z magento, pobiera zamówienia, dla każdego zamówienia tworzy fakturkę sprzedaży i do tej fakturki dodaje pozycje z zamówienia, na końcu sprawdza jeszcze rodzaj wysyłki wybrany do zamówienia i wstawia odpowiednią dostawę, która jest towarem typu: usługa w subiekcie ;)
Patrzy ile ten towar kosztuje i widzi cenę netto 13,11 :)
Wylicza więc VAT i wychodzi mu: 2,8842zł (13,11*22/100)
Radośnie dodaje VAT do kwoty netto: 13,11 + 2,8842 = 15,9942zł
Jako, że na fakturach musimy podać cenę w złotówkach kwota jest zaokrąglana do 2óch miejsc po przecinku robi więc round($cena_brutto,2); i wychodzi mu 15,99zł :)
Po długim bezskutecznym kombinowaniu jak by to wyliczyć, żeby wyszło 16,00zł wpadłem na pomysł - WPISZĘ 13,11 JAKO NETTO DO SUBIEKTA I ZOBACZĘ CO POWIE !
Subiekt mówi cena brutto: 15,99zł
Czyli cena netto z 16zł wynosi 13,11zł, a cena brutto z 13,11zł wynosi: 15,99zł ;)
Na koniec spróbowałem wystawić fakturę ręcznie dodając do niej dostawę - efekt: koszt dostawy na fakturze: 15,99zł :)
Wydaje się to błahostką, ale jednak taki klient, który wybrał koszt dostawy 16zł w sklepie, może czułby się bardziej komfortowo, gdyby na fakturze też było 16zł. Np gdybym to ja kupował i żona by zobaczyła fakturę i że oszukałem ją o grosik, przecież nie chodzi o kwotę, chodzi o zasadę!!!... nie no trochę zabrnąłem, ale może ktoś mi potrafi wyjaśnić, czy możliwe jest sprzedanie produktu w cenie 16zł brutto i wystawienie na niego faktury przy użyciu najnowszych technologii!?!?
Dzisiaj zauważono, że w programie subiekt na fakturze w pozycji koszt wysyłki zamiast 16,00zł wchodzi kwota 15,99zł - wniosek: programista oszukuje na grosiki (jak kiedyś ponoć jedna Pani w sklepiku szkolnym). Na fakturę wchodzi pozycja z produktem z Subiekta, któremu wpisano cenę brutto 16zł, a subiekt sam wyliczył cenę netto (przy podatku VAT 22%) w kwocie: 13,11zł.
Co robi program importu?
Łączy się z magento, pobiera zamówienia, dla każdego zamówienia tworzy fakturkę sprzedaży i do tej fakturki dodaje pozycje z zamówienia, na końcu sprawdza jeszcze rodzaj wysyłki wybrany do zamówienia i wstawia odpowiednią dostawę, która jest towarem typu: usługa w subiekcie ;)
Patrzy ile ten towar kosztuje i widzi cenę netto 13,11 :)
Wylicza więc VAT i wychodzi mu: 2,8842zł (13,11*22/100)
Radośnie dodaje VAT do kwoty netto: 13,11 + 2,8842 = 15,9942zł
Jako, że na fakturach musimy podać cenę w złotówkach kwota jest zaokrąglana do 2óch miejsc po przecinku robi więc round($cena_brutto,2); i wychodzi mu 15,99zł :)
Po długim bezskutecznym kombinowaniu jak by to wyliczyć, żeby wyszło 16,00zł wpadłem na pomysł - WPISZĘ 13,11 JAKO NETTO DO SUBIEKTA I ZOBACZĘ CO POWIE !
Subiekt mówi cena brutto: 15,99zł
Czyli cena netto z 16zł wynosi 13,11zł, a cena brutto z 13,11zł wynosi: 15,99zł ;)
Na koniec spróbowałem wystawić fakturę ręcznie dodając do niej dostawę - efekt: koszt dostawy na fakturze: 15,99zł :)
Wydaje się to błahostką, ale jednak taki klient, który wybrał koszt dostawy 16zł w sklepie, może czułby się bardziej komfortowo, gdyby na fakturze też było 16zł. Np gdybym to ja kupował i żona by zobaczyła fakturę i że oszukałem ją o grosik, przecież nie chodzi o kwotę, chodzi o zasadę!!!... nie no trochę zabrnąłem, ale może ktoś mi potrafi wyjaśnić, czy możliwe jest sprzedanie produktu w cenie 16zł brutto i wystawienie na niego faktury przy użyciu najnowszych technologii!?!?
Magento i platnosci.pl brak kosztu wysyłki
Napotkałem niemiły błąd w sklepie opartym na magento związany z modułem platnosci.pl. Polega on na tym, że przy zamówieniu produktu i próbie zapłacenia za pomocą platnosci.pl do ceny nie jest doliczany koszt wysyłki. Wynika to z błędu w module płatności (wersja 1.1).
Aby się go pozbyć należy w pliku: /app/code/local/Mage/Platnosci/Model/Payment.php
zmienić linię nr: zmienić na: i już :) Rozwiązanie nie jest mojego autorstwa - leży sobie tutaj schowane jako uwaga do modułu dodana przez "Janka".
Aby się go pozbyć należy w pliku: /app/code/local/Mage/Platnosci/Model/Payment.php
zmienić linię nr: zmienić na: i już :) Rozwiązanie nie jest mojego autorstwa - leży sobie tutaj schowane jako uwaga do modułu dodana przez "Janka".
wtorek, 14 września 2010
PicsEngine Declaration of AppOptions::get() should be compatible with that of SystemObject::get()
Błąd z tematu pojawia się po wejściu na stronę galerii PicsEngine po aktualizacji PHP do wersji 5.3.3 na serwerze, na którym galeria stoi ;) Problem polega na tym, że o takiej aktualizacji hostingowcy nas często nawet nie poinformują ;)
Cała niemiła sytuacja objawia się komunikatem z obrazka:

Sprawę rozwiązuje aktualizacja PicsEngine do wersji 3.5 lub wyższej... w zależności od tego z której wersji korzystaliśmy dotąd problem sprowadza się do przeniesienia katalogów /admin/conf/ i /admin/cache/ o jeden poziom w górę i wgrania nowych plików, lub skorzystania z instrukcji pod adresem: http://www.picsengine.com/en/support/update-guide
Cała niemiła sytuacja objawia się komunikatem z obrazka:
sobota, 7 sierpnia 2010
SIEROTY i WDOWY na stronie, justowanie tekstu
Na stronach internetowych nie ma raczej zwyczaju doskonałego formatowania tekstu, ale zawsze możemy trafić na klienta, który ma coś więcej wspólnego z typografią i powie nam, że to niedopuszczalne żeby w wyjustowanym tekście były literki "i", czy inne pojedyncze znaki na końcu linii. Trudno żebyśmy teraz siedzieli i poprawiali każdy tekst na stronie, który często jest w dodatku kopiowany i wstawiany przez CMS...
Kiedyś wykombinowałem na to prosty skrypcik, który pozwolił uspokoić 2óch bardziej wymagających klientów, a wygląda on tak: Skrypt wciska tzw. "twardą spację" ( jak mówił Pan z PHP skrót od: "niech będą spacje") po każdym jednoznakowym słowie - wtedy automatycznie to słowo doklei się do kolejnego tak, jakby były jednym wyrazem. Dwu-znakowe i trzy-znakowe zakomentowane, bo uważam to za przesadę, a w dodatku z 3znakowymi jeśli mamy w tekście 3znakowe tagi to też pozamienia i nie zawsze to wyjdzie na dobre :)
tekst powinien się znajdować w elemencie o ID='tresc', ale to chyba widać ;)
Kiedyś wykombinowałem na to prosty skrypcik, który pozwolił uspokoić 2óch bardziej wymagających klientów, a wygląda on tak: Skrypt wciska tzw. "twardą spację" ( jak mówił Pan z PHP skrót od: "niech będą spacje") po każdym jednoznakowym słowie - wtedy automatycznie to słowo doklei się do kolejnego tak, jakby były jednym wyrazem. Dwu-znakowe i trzy-znakowe zakomentowane, bo uważam to za przesadę, a w dodatku z 3znakowymi jeśli mamy w tekście 3znakowe tagi to też pozamienia i nie zawsze to wyjdzie na dobre :)
tekst powinien się znajdować w elemencie o ID='tresc', ale to chyba widać ;)
Lista województw PHP tablica
Widzę, że lista państw się przydała to może przyda się też lista województw. Krótsza, więc od biedy można zrobić ręcznie, ale chyba wygodniej skopiować poniższą tablicę PHP:
niedziela, 25 lipca 2010
Domeny .co okazja?
22-07-2010 ruszyła rejestracja domen .co (Kolumbia). W Polsce pierwszy udostępnił je home.pl i okazały się ponoć niezłym hitem. "CO" może być kojarzone ze skrótem od takich angielskich słów jak company, corporation, czy commerce, dlatego domena ma być lepsza niż inne (podobnie jak .tv, czy .fm).
Zachęcony newsem spędziłem całe popołudnie sprawdzając dostępność różnych domen jakie wpadały mi do głowy ;)
Metody poszukiwań:
1. popularne frazy wg googla i rankingów
2. przegląd drogich/często odwiedzanych domen
3. nazwy miast i regionów
4. opcje z literówkami
5. przegląd poważniejszych witryn w popularnej domenie .co.uk
Efekty:
No cóż pojawiło się trochę domen, które na pozór wydały się atrakcyjne, ale po dłuższym na myślę nie kupiłem nic :)
Na początek coś z branży: tworzenie-stron.co, a nawet strony.co - tylko czy bycie na pierwszej stronie na te frazy nie będzie kosztowało więcej wysiłku niż przynosiło korzyści??
czcionka.co, czcionki.co, skrypty.co, chomik.co, chomikuj.co, sieci.co - niby fajne, ale chyba ciężko by było z tego wiele wycisnąć...
dziewczyny.co, azjatki.co - czyli coś pod stronę porno, która linkuje do kolejnej strony porno, a ta do kolejnej, w między czasie mamy już otwartych 20 okienek i wszystkie bez sensu, ale ktoś coś na tym chyba zarabia skoro się w to bawi :)
windows-7.co - spóźniona, beskidy.co - ale beskidy to nie bardzo korporacja ;), kult.co - chyba tylko z sympatii do zespołu, filmy-online.co - może jeśli ktoś ma ochotę konkurować z największymi, cash-flow.co - jedyne co mi się spodobało po angielsku, cieszyn.co - jako jedno z nielicznych niezajętych miast, budownictwo.co - na kolejny katalog firm, kursy.co - tutaj już prawie zarejestrowałem, ale wszedłem na kursy.pl i stwierdziłem, że to nie dla mnie ;)
Podstawowy problem: .co pasuje pod stronę angielskojęzyczną, a domeny z angielskimi słowami są pozajmowane ;) fajną zdobyczą mogłaby być domena pomysłowa typu: kotly.co, domena z bardzo popularnym słowem/frazą, znana domena bez ".uk" na końcu - ale na to już chyba trochę za późno - zostały ochłapy :)
Koszt rejestracji 99zł netto to nie złotówka, więc człowiek nie wejdzie i nie zarejestruje 50 domen na zasadzie "a może się przyda"...
Myślę, że do wzięcia jest trochę krótkich abstrakcyjnych nazw typu: westa.co i mniej hitowe ale niezłe do pozycjonowania domeny z popularnymi frazami... maja
Zachęcony newsem spędziłem całe popołudnie sprawdzając dostępność różnych domen jakie wpadały mi do głowy ;)
Metody poszukiwań:
1. popularne frazy wg googla i rankingów
2. przegląd drogich/często odwiedzanych domen
3. nazwy miast i regionów
4. opcje z literówkami
5. przegląd poważniejszych witryn w popularnej domenie .co.uk
Efekty:
No cóż pojawiło się trochę domen, które na pozór wydały się atrakcyjne, ale po dłuższym na myślę nie kupiłem nic :)
Na początek coś z branży: tworzenie-stron.co, a nawet strony.co - tylko czy bycie na pierwszej stronie na te frazy nie będzie kosztowało więcej wysiłku niż przynosiło korzyści??
czcionka.co, czcionki.co, skrypty.co, chomik.co, chomikuj.co, sieci.co - niby fajne, ale chyba ciężko by było z tego wiele wycisnąć...
dziewczyny.co, azjatki.co - czyli coś pod stronę porno, która linkuje do kolejnej strony porno, a ta do kolejnej, w między czasie mamy już otwartych 20 okienek i wszystkie bez sensu, ale ktoś coś na tym chyba zarabia skoro się w to bawi :)
windows-7.co - spóźniona, beskidy.co - ale beskidy to nie bardzo korporacja ;), kult.co - chyba tylko z sympatii do zespołu, filmy-online.co - może jeśli ktoś ma ochotę konkurować z największymi, cash-flow.co - jedyne co mi się spodobało po angielsku, cieszyn.co - jako jedno z nielicznych niezajętych miast, budownictwo.co - na kolejny katalog firm, kursy.co - tutaj już prawie zarejestrowałem, ale wszedłem na kursy.pl i stwierdziłem, że to nie dla mnie ;)
Podstawowy problem: .co pasuje pod stronę angielskojęzyczną, a domeny z angielskimi słowami są pozajmowane ;) fajną zdobyczą mogłaby być domena pomysłowa typu: kotly.co, domena z bardzo popularnym słowem/frazą, znana domena bez ".uk" na końcu - ale na to już chyba trochę za późno - zostały ochłapy :)
Koszt rejestracji 99zł netto to nie złotówka, więc człowiek nie wejdzie i nie zarejestruje 50 domen na zasadzie "a może się przyda"...
Myślę, że do wzięcia jest trochę krótkich abstrakcyjnych nazw typu: westa.co i mniej hitowe ale niezłe do pozycjonowania domeny z popularnymi frazami... maja
poniedziałek, 14 czerwca 2010
CRONTAB w home.pl
Na serwerach home.pl brakuje dostępu do crontaba :( ALE okazuje się, że mają swoje rozwiązanie - mające pewne ograniczenia, ale zdające egzamin w większości przypadków. Na serwerze w katalogu głównym umieszczamy plik, którego nazwa mówi, jak często ma być uruchamiany np:
cron-daily.php - będzie uruchamiany raz na dzień...
cron-hourly.php - będzie uruchamiany raz na godzinę...
Najczęściej pozwalają nam odpalać skrypt co 5 minut: cron-5min.pl
Można też robić kombinacje typu:
cron-04.php - codziennie o 4:00
Jest tam jeszcze kilka opcji - szczegóły w dokumentacji.
Nie zawsze chcemy nazywać pliki w ten sposób i nie zawsze pasuje nam umieszczanie ich w katalogu głównym, ale nie szkodzi nam w śmiesznym pliczku: cron-daily.php napisać:
file_get_contents('http://programistawww.pl/crontab.php');
W niektórych wypadkach 5 minut to może być za rzadko, tylko, że w tych wypadkach zazwyczaj aplikacja stoi na serwerze dedykowanym, gdzie jest dostęp do crona ;)
cron-daily.php - będzie uruchamiany raz na dzień...
cron-hourly.php - będzie uruchamiany raz na godzinę...
Najczęściej pozwalają nam odpalać skrypt co 5 minut: cron-5min.pl
Można też robić kombinacje typu:
cron-04.php - codziennie o 4:00
Jest tam jeszcze kilka opcji - szczegóły w dokumentacji.
Nie zawsze chcemy nazywać pliki w ten sposób i nie zawsze pasuje nam umieszczanie ich w katalogu głównym, ale nie szkodzi nam w śmiesznym pliczku: cron-daily.php napisać:
file_get_contents('http://programistawww.pl/crontab.php');
W niektórych wypadkach 5 minut to może być za rzadko, tylko, że w tych wypadkach zazwyczaj aplikacja stoi na serwerze dedykowanym, gdzie jest dostęp do crona ;)
czwartek, 27 maja 2010
OBSŁUGA PŁATNOŚCI.PL W PHP
Musiałem ostatnio dorobić moduł płatności do strony, gdzie nie dało się zainstalować gotowego modułu, bo go nie było :) Z szybkiego przeglądu forów wynika, że bractwo programistyczne niechętnie dzieli się kodem w tym temacie. Ja postanowiłem się podzielić podstawowym kodem. Pewnie będzie wymagał dopracowania, ale zawsze lepiej zacząć od czegoś, co chociaż w części jest zrobione.
1. Nasz skrypt wysyła POST na stronę platnosci.pl z parametrami, z których obowiązkowe to:
- pos_id - numer tzw POSa (punktu usługowego), czyli jakby jednostki przez którą ma to iść, można takich tworzyć wiele na jednym koncie i różnie je konfigurować,
- pos_auth_key - kod autoryzacyjny nadany przez serwis płatności,
- session_id - unikalny identyfikator,
- amount - kwota zakupu w groszach,
- desc - krótki opis,
- js - info, czy przeglądarka klienta obsługuje JS
- first_name, last_name, client_ip, email - czyli wiadomo.
2. Klient coś tam sobie klika po ich stronie i na końcu jest przekierowany na jeden z dwóch adresów, które podajemy w konfiguracji:
- pierwszy jest w sytuacji jak wszystko poszło OK np: mojadomena.pl/ok.php
- drugi w sytuacji kiedy coś nawaliło np: mojadomena.pl/error.php
do obydwu adresów mogą być przekazane dodatkowe parametry GETem np: mojadomena.pl/error.php?error=%error_id%&order_id=%order_id%
UWAGA PRZEKIEROWANIE NA ok.php NIE OZNACZA, ŻE MAMY JUŻ KASĘ NA KONCIE - OZNACZA, ŻE RACZEJ POSZŁO OK, ALE TRZEBA TO SPRAWDZIĆ.
3. Ostatni etap to sprawdzanie statusów płatności. Nie potrzebujemy do tego crona. Platnosci.pl same informują nas o tym, że zaszła zmiana i wtedy musimy ją pobrać. Służy do tego 3 skrypt: mojadomena.pl/online.php Jest on wywoływany przez pltnosci.pl w momencie gdy zajdzie jakaś zmiana i wtedy on sam powinien zapytać płatności o zmianę i ją obsłużyć.
ad2. Jako error.php i ok.php posłuży skrypt z szablonem naszej strony, który w części głównej wypluje coś w rodzaju: ok.php jest analogiczny, tylko bez errora i z weselszym tytułem, więc nie piszę...
ad3. I na koniec zostaje plik komunikujący się "na serio" z płatnościami: online.php - też mój, ale wykorzystane fragmenty kodu modułu płatności do prestashopa, bo tak prościej.
Pliki są wycięte z wersji beta aplikacji, którą piszę, następnie okrojone i dodatkowo okomentowane i po tym okrojeniu już nie testowane, więc mogły wkraść się drobne błędy ;) Myślę, że z nimi dużo łatwiej niż z samą treścią dokumentacji ;)
Jak działają platnosci.pl w skrócie
Oczywiście pisząc moduł dobrze się zapoznać z dokumentacją techniczną, ale chodzi mi o skrót, który wygląda mniej więcej tak:1. Nasz skrypt wysyła POST na stronę platnosci.pl z parametrami, z których obowiązkowe to:
- pos_id - numer tzw POSa (punktu usługowego), czyli jakby jednostki przez którą ma to iść, można takich tworzyć wiele na jednym koncie i różnie je konfigurować,
- pos_auth_key - kod autoryzacyjny nadany przez serwis płatności,
- session_id - unikalny identyfikator,
- amount - kwota zakupu w groszach,
- desc - krótki opis,
- js - info, czy przeglądarka klienta obsługuje JS
- first_name, last_name, client_ip, email - czyli wiadomo.
2. Klient coś tam sobie klika po ich stronie i na końcu jest przekierowany na jeden z dwóch adresów, które podajemy w konfiguracji:
- pierwszy jest w sytuacji jak wszystko poszło OK np: mojadomena.pl/ok.php
- drugi w sytuacji kiedy coś nawaliło np: mojadomena.pl/error.php
do obydwu adresów mogą być przekazane dodatkowe parametry GETem np: mojadomena.pl/error.php?error=%error_id%&order_id=%order_id%
UWAGA PRZEKIEROWANIE NA ok.php NIE OZNACZA, ŻE MAMY JUŻ KASĘ NA KONCIE - OZNACZA, ŻE RACZEJ POSZŁO OK, ALE TRZEBA TO SPRAWDZIĆ.
3. Ostatni etap to sprawdzanie statusów płatności. Nie potrzebujemy do tego crona. Platnosci.pl same informują nas o tym, że zaszła zmiana i wtedy musimy ją pobrać. Służy do tego 3 skrypt: mojadomena.pl/online.php Jest on wywoływany przez pltnosci.pl w momencie gdy zajdzie jakaś zmiana i wtedy on sam powinien zapytać płatności o zmianę i ją obsłużyć.
implementacja
ad1. Ta część jest prosta i zrealizuje ją prosty formularz, przykładowy jest w klasie platnoscipl - mojego autorstwa, ale mocno inspirowana klasą z prestashopa ;)w metodzie: orderForm(). Prawie identyczny formularz jest w dokumentacji platnosci.pl. Przed wyświetleniem formularza należy stworzyć order metodą podobną do: createOrder(); żeby się ustawiły pola w klasie platnoscipl wykorzystywane w formularzu;]ad2. Jako error.php i ok.php posłuży skrypt z szablonem naszej strony, który w części głównej wypluje coś w rodzaju: ok.php jest analogiczny, tylko bez errora i z weselszym tytułem, więc nie piszę...
ad3. I na koniec zostaje plik komunikujący się "na serio" z płatnościami: online.php - też mój, ale wykorzystane fragmenty kodu modułu płatności do prestashopa, bo tak prościej.
Pliki są wycięte z wersji beta aplikacji, którą piszę, następnie okrojone i dodatkowo okomentowane i po tym okrojeniu już nie testowane, więc mogły wkraść się drobne błędy ;) Myślę, że z nimi dużo łatwiej niż z samą treścią dokumentacji ;)
poniedziałek, 24 maja 2010
Losowe daty w MySQL
Generowałem ostatnio bazę danych katalogu stron i już po uruchomieniu zorientowałem się, że dobrze by było jak by wpisy miały zróżnicowane daty.
Można to uzyskać pisząc jedno sprytne zapytanie do bazy:
2010-01-01 - to data początkowa
150 - to liczba dni jaką MAKSYMALNIE dodajemy do daty początkowej generując kolejne daty
Jeszcze by się jakiemuś robotowi nie spodobało, że wszystkie wpisy mają jedną datę ;)
Można to uzyskać pisząc jedno sprytne zapytanie do bazy:
2010-01-01 - to data początkowa
150 - to liczba dni jaką MAKSYMALNIE dodajemy do daty początkowej generując kolejne daty
Jeszcze by się jakiemuś robotowi nie spodobało, że wszystkie wpisy mają jedną datę ;)
piątek, 21 maja 2010
WYŁĄCZYĆ HINT z ALT-em OBRAZKA w IE
Korzystając ze skryptów prezentujących obrazki często wpadamy na pomysł, żeby wykorzystać atrybuty alt, lub title w sposób inny niż wynika z ich HTML-owego przeznaczenia.
W jednym z ostatnich projektów wykorzystywałem skrypt imageflow, który atrybut alt obrazka wyświetla jako etykietę. Do alta wstawiłem więc ostylowaną tabelę. Wszystko działa, skrypt pobiera z atrybutu alt kod HTML i wstawia go do właściwego DIV-a...
PROBLEM W TYM, ŻE IE PO NAJECHANIU WYŚWIETLA KOD TABELI :(
Rozwiązanie okazuje się proste: Czyli jeśli wpiszemy title='' to IE nie będzie wyświetlał hinta z altem. Żeby się za dużo nie napisać można to zmienić skryptem. W imageflow po linii 566 dopisać:
W jednym z ostatnich projektów wykorzystywałem skrypt imageflow, który atrybut alt obrazka wyświetla jako etykietę. Do alta wstawiłem więc ostylowaną tabelę. Wszystko działa, skrypt pobiera z atrybutu alt kod HTML i wstawia go do właściwego DIV-a...
PROBLEM W TYM, ŻE IE PO NAJECHANIU WYŚWIETLA KOD TABELI :(
Rozwiązanie okazuje się proste: Czyli jeśli wpiszemy title='' to IE nie będzie wyświetlał hinta z altem. Żeby się za dużo nie napisać można to zmienić skryptem. W imageflow po linii 566 dopisać:
czwartek, 6 maja 2010
ZNIKANIE TREŚCI STRONY - ROBOTY
Kilka dni temu robiłem modyfikacje na portalu opartym o live framework. Nie jestem autorem kodu, ale zmiany nie były duże, wymagały jedynie rozbudowy jednej tabeli i drobnych zmian w zapytaniach.
Po kliku dniach okazało się, że ze strony zniknęła większość artykułów oraz ogłoszeń. Pomimo ciężkich rozmyślań nad możliwością namieszania czegoś przeze mnie nie mogłem dojść jak modyfikacja kilku selectów i skórek mogą by spowodować skasowanie danych z bazy mysql. Rozmyślanie było tym bardziej utrudnione, ponieważ spora część kodu strony była zaszyfrowana.
Właściwie pozostało mi zdenerwowanie, że z powodu zmian wartych kilka groszy wyjdę na gościa, co psuje portale... i wtedy znalazłem ARTYKUŁ.
Okazało się, że rzeczywiście administratorka portalu miała zainstalowany alexa toolbar, a w panelu linki do kasowania artykułów były zwykłymi linkami (bez żadnego skryptowego potwierdzenia itp...). Prawdopodobnie sama aplikacja alexa toolbar łazi po wszystkich linkach jakie widzi (a nie robot komunikujący się z aplikacją - to przypuszczenie, ale tak chyba prościej), ale wszystko jedno - pewne jest to, że jest to trudna do przewidzenia dziura, która może być w wielu systemach. Ciężko się zabezpieczyć przed czymś, co działa po stronie zalogowanej do panelu przeglądarki... Taka aplikacja może zrobić właściwie wszystko co może zrobić użytkownik: skasować, zrobić zakupy, a może nawet zrobić przelew??
Wczoraj robiłem porządek na komputerze żony i znalazłem na nim z 5 toolbarów: skype, winamp i jakieś mało znane. Oczywiście nie muszę dodawać, że żaden z nich nie był przez nią używany - nawet nie wiedziała co to jest ;)
DLATEGO LUDZIE PATRZCIE CO INSTALUJECIE, BO ONE SIĘ SAME NIE INSTALUJĄ!!!!
Po kliku dniach okazało się, że ze strony zniknęła większość artykułów oraz ogłoszeń. Pomimo ciężkich rozmyślań nad możliwością namieszania czegoś przeze mnie nie mogłem dojść jak modyfikacja kilku selectów i skórek mogą by spowodować skasowanie danych z bazy mysql. Rozmyślanie było tym bardziej utrudnione, ponieważ spora część kodu strony była zaszyfrowana.
Właściwie pozostało mi zdenerwowanie, że z powodu zmian wartych kilka groszy wyjdę na gościa, co psuje portale... i wtedy znalazłem ARTYKUŁ.
Okazało się, że rzeczywiście administratorka portalu miała zainstalowany alexa toolbar, a w panelu linki do kasowania artykułów były zwykłymi linkami (bez żadnego skryptowego potwierdzenia itp...). Prawdopodobnie sama aplikacja alexa toolbar łazi po wszystkich linkach jakie widzi (a nie robot komunikujący się z aplikacją - to przypuszczenie, ale tak chyba prościej), ale wszystko jedno - pewne jest to, że jest to trudna do przewidzenia dziura, która może być w wielu systemach. Ciężko się zabezpieczyć przed czymś, co działa po stronie zalogowanej do panelu przeglądarki... Taka aplikacja może zrobić właściwie wszystko co może zrobić użytkownik: skasować, zrobić zakupy, a może nawet zrobić przelew??
Wczoraj robiłem porządek na komputerze żony i znalazłem na nim z 5 toolbarów: skype, winamp i jakieś mało znane. Oczywiście nie muszę dodawać, że żaden z nich nie był przez nią używany - nawet nie wiedziała co to jest ;)
DLATEGO LUDZIE PATRZCIE CO INSTALUJECIE, BO ONE SIĘ SAME NIE INSTALUJĄ!!!!
środa, 5 maja 2010
Scuttle - tworzenie zaplecza
Polecam artykuł :)
i zapraszam na stronę: jezyk-angielski.eu, która jest jednocześnie testem tego skryptu :) odezwę się w przyszłości, jeśli okaże się testem udanym :)
i zapraszam na stronę: jezyk-angielski.eu, która jest jednocześnie testem tego skryptu :) odezwę się w przyszłości, jeśli okaże się testem udanym :)
poniedziałek, 3 maja 2010
KOLEJNOŚĆ ŁADOWANIA PLIKÓW index.html, index.php - .htaccess
Krótka informacja jak zmusić serwer do załadowania tego, czego chcemy, jeśli użytkownik nie wpisze nazwy pliku. Domyślnie zwykle jest ładowany plik index.html, jeśli takiego nie ma to index.php itd...
Kolejność można zmienić w pliku .htaccess, jeśli mamy do niego dostęp za pomocą instrukcji:
DirectoryIndex index.php index.html
możemy tam wypisać dowolne pliki oddzielone spacją. Należy zwrócić uwagę, że jeśli w katalogu nie znajduje się żaden z wymienionych plików, to serwer może wyświetlić listing katalogu, co nie zawsze jest wskazane.
Kolejność można zmienić w pliku .htaccess, jeśli mamy do niego dostęp za pomocą instrukcji:
DirectoryIndex index.php index.html
możemy tam wypisać dowolne pliki oddzielone spacją. Należy zwrócić uwagę, że jeśli w katalogu nie znajduje się żaden z wymienionych plików, to serwer może wyświetlić listing katalogu, co nie zawsze jest wskazane.
sobota, 1 maja 2010
ANTYPLAGIAT CO POTRAFI?
Generalnie wydaje mi się, że antyplagiat, jest przez środowiska uczelniane mocno przeceniany i jawi się jako system, który wykrywa w pracach podobieństwa, o których nawet sam "autor" nie wie. Nie znam tego systemu od strony technicznej, ale moim zdaniem w obecnych czasach przeciętny system informatyczny nie jest w stanie wykryć takich rzeczy jak:
- tłumaczenie tekstu - nie potrafi przetłumaczyć, więc tym bardziej porównać tłumaczenia, on chyba w ogóle nie sprawdza tłumaczenia, ale nawet gdyby sprawdzał to może to zrobić bardzo prymitywnie,
- streszczony większy fragment - nie "rozumie" sensu, więc nie widzi związku miedzy tekstem źródłowym a streszczeniem, zresztą streszczenie nie jest plagiatem,
- tekst sparafrazowany i przemieszany - jest w stanie na podstawie powtarzania się wyrazów (czy ich synonimów, chociaż tutaj pewnie w ograniczony sposób) w dłuższym fragmencie tekstu stwierdzić podobieństwo między tym fragmentem, a fragmentem źródłowym. ALE TYLKO w sytuacji jeżeli ktoś parafrazował zdanie po zdaniu (i to jeszcze prymitywnie, robiąc tylko jakieś przestawienia), jeżeli natomiast zdania są parafrazowane, a w dodatku przemieszane zdaniami własnymi, albo zaczerpniętymi z innego źródła, to nie ma wystarczająco długich fragmentów, żeby można było stwierdzić podobieństwo. Chyba, że próbował by składać różne fragmenty z ułożonych zdań i porównywać, ale złożoność by okropnie wzrosła, a i tak by pewnie niewiele z tego było, bo zaraz by się okazało, że każdy tekst jest plagiatem każdego :)
Dodatkowo:
- nie każde źródło internetowe z założenia jest w bazie antyplagiatu - pomijając same ograniczenia co do objętości internetu, dochodzą różne zabezpieczenia publikowanych materiałów (uniemożliwiające ich automatyczne kopiowanie), lub wynikające z samego formatu plików - np: analiza tekstu zawartego w pliku graficznym jest na tyle kłopotliwa, że z pewnością takie teksty nie są brane pod uwagę, pliki flash, zabezpieczone PDF-y, pliki spakowane (zabezpieczone hasłem), materiały dostępne po zalogowaniu, dostępne w sieciach P2P itd. itp.
Podsumowując moja uproszczona wizja tego systemu, jest taka, że:
- posiada bazę najpopularniejszych źródeł do najpopularniejszych tematów + bazę synonimów,
- szuka w tej bazie przede wszystkim powtarzających się fragmentów i fraz, oraz powtarzających się podobnych fragmentów (czyli z tymi samymi słowami, lub ich przestawieniami),
- potrafi do tego policzyć proste statystyki i tyle....
Dlaczego więc taki straszny?
Moje zdanie jest bezwzględne jak ten system:
Ludzie od dawna przeklepują (bardziej lub mniej bezmyślnie) książki. Jeszcze niedawno OCR był uważany za niezbędnik podczas pisania pracy, bo można przeskanować książkę i wkleić do pracy bez przepisywania - HURRA ;) W dodatku mają podobne i szablonowe tematy, które często dostają na liście do wyboru do obdzielenia się (ciekawe czy lista powtarza się co roku, czy chociaż co 2 lata). Korzystają z tych samych źródeł - zarówno jeśli chodzi o książki, bo albo biorą to co jest w bibliotece, albo to, co poleca promotor (trudno żeby każdemu polecił co innego), jak i o źródła internetowe (pierwsze wyniki google, wikipedia itp.). Ze strachu przed antyplagiatem robią masę przypisów, bo przecież mają przypis, więc to nie jest plagiat, a dla systemu tytuł książki w przypisie to tylko kolejny powtórzony tekst. Marnują czas na sztuczne przestawianie wyrazów i szukanie synonimów, zamiast przeczytać 2 strony w dwóch źródłach i napisać o czym one są... Boją się napisać czegokolwiek samemu, czegoś, co wynika z książki, ale nie jest w niej wyklepane czarno na białym. Przecież można napisać zdanie wniosku, własny przekład, cokolwiek. Jak to będzie naiwne, nieciekawe, czy bez sensu to nic się takiego chyba nie stanie - najwyżej będzie trzeba albo swój pomysł obronić, albo powiedzieć: "OK nie mam racji" i albo zmienić, albo trudno - już poszło ;) Niestety ludzie uwielbiają używać argumentu: "Przecież tak jest w książce"...( w domyśle: "Sami mi ją kazaliście przeczytać to się teraz odczepcie").
Człowiek, którego praca jest frankensteinem złożonym na szybko z wikipedii, innych prac półfrankensteinów i książkowych definicji w momencie kiedy nie przepuszcza jej antyplagiat i robi się afera nie powie przecież:
"Tak skopiowałem to na szybko w ciągu ostatniego tygodnia i z braku czasu nie testowałem w necie za 30zł, tylko oddałem - co miałem do stracenia i tak już po terminie by było...". Będzie za to udawał wielkie zdziwienie, mówił jak to brutalny system jest niesprawiedliwy itd... Promotor ma masę prac do sprawdzenia, pełno studentów, którzy przychodzą, albo nie na te seminaria, mało czasu, dużo pracy, stara się być wyrozumiały, sam w końcu kiedyś przechodził coś podobnego i z perspektywy widzi, że nie była to najważniejsza sprawa w jego życiu. Stara się więc problem plagiatu załagodzić, trochę broni studenta, jest lekko sceptycznie nastawiony do systemu... Student skarży się kolegom na niedobry antyplagiat, sprawa roznosi się dalej i dalej... każdy dokłada swoje 3 grosze, że mu to i tamto podkreśliło, "a przecież zmieniał" (miał pisać a nie zmieniać)... Powstaje mit systemu, który jest tak sprawny, że autorom science fiction się o podobnym nie śniło.
ALE
Wszystko wskazuje na to, że jest to stosunkowo proste narzędzie, które wykrywa tylko najbardziej bezmyślne, bezczelne i leniwe kopiowanie ;)
Dla wszystkich, którzy są przerażeni systemem wynik przetestowania 2óch pierwszych rozdziałów mojej pracy, które wielkim dziełem na prawdę nie są ;) (to 0.3 to tytuł ksiązkiw stawiony 3 razy jako op. cit.)

- tłumaczenie tekstu - nie potrafi przetłumaczyć, więc tym bardziej porównać tłumaczenia, on chyba w ogóle nie sprawdza tłumaczenia, ale nawet gdyby sprawdzał to może to zrobić bardzo prymitywnie,
- streszczony większy fragment - nie "rozumie" sensu, więc nie widzi związku miedzy tekstem źródłowym a streszczeniem, zresztą streszczenie nie jest plagiatem,
- tekst sparafrazowany i przemieszany - jest w stanie na podstawie powtarzania się wyrazów (czy ich synonimów, chociaż tutaj pewnie w ograniczony sposób) w dłuższym fragmencie tekstu stwierdzić podobieństwo między tym fragmentem, a fragmentem źródłowym. ALE TYLKO w sytuacji jeżeli ktoś parafrazował zdanie po zdaniu (i to jeszcze prymitywnie, robiąc tylko jakieś przestawienia), jeżeli natomiast zdania są parafrazowane, a w dodatku przemieszane zdaniami własnymi, albo zaczerpniętymi z innego źródła, to nie ma wystarczająco długich fragmentów, żeby można było stwierdzić podobieństwo. Chyba, że próbował by składać różne fragmenty z ułożonych zdań i porównywać, ale złożoność by okropnie wzrosła, a i tak by pewnie niewiele z tego było, bo zaraz by się okazało, że każdy tekst jest plagiatem każdego :)
Dodatkowo:
- nie każde źródło internetowe z założenia jest w bazie antyplagiatu - pomijając same ograniczenia co do objętości internetu, dochodzą różne zabezpieczenia publikowanych materiałów (uniemożliwiające ich automatyczne kopiowanie), lub wynikające z samego formatu plików - np: analiza tekstu zawartego w pliku graficznym jest na tyle kłopotliwa, że z pewnością takie teksty nie są brane pod uwagę, pliki flash, zabezpieczone PDF-y, pliki spakowane (zabezpieczone hasłem), materiały dostępne po zalogowaniu, dostępne w sieciach P2P itd. itp.
Podsumowując moja uproszczona wizja tego systemu, jest taka, że:
- posiada bazę najpopularniejszych źródeł do najpopularniejszych tematów + bazę synonimów,
- szuka w tej bazie przede wszystkim powtarzających się fragmentów i fraz, oraz powtarzających się podobnych fragmentów (czyli z tymi samymi słowami, lub ich przestawieniami),
- potrafi do tego policzyć proste statystyki i tyle....
Dlaczego więc taki straszny?
Moje zdanie jest bezwzględne jak ten system:
Ludzie od dawna przeklepują (bardziej lub mniej bezmyślnie) książki. Jeszcze niedawno OCR był uważany za niezbędnik podczas pisania pracy, bo można przeskanować książkę i wkleić do pracy bez przepisywania - HURRA ;) W dodatku mają podobne i szablonowe tematy, które często dostają na liście do wyboru do obdzielenia się (ciekawe czy lista powtarza się co roku, czy chociaż co 2 lata). Korzystają z tych samych źródeł - zarówno jeśli chodzi o książki, bo albo biorą to co jest w bibliotece, albo to, co poleca promotor (trudno żeby każdemu polecił co innego), jak i o źródła internetowe (pierwsze wyniki google, wikipedia itp.). Ze strachu przed antyplagiatem robią masę przypisów, bo przecież mają przypis, więc to nie jest plagiat, a dla systemu tytuł książki w przypisie to tylko kolejny powtórzony tekst. Marnują czas na sztuczne przestawianie wyrazów i szukanie synonimów, zamiast przeczytać 2 strony w dwóch źródłach i napisać o czym one są... Boją się napisać czegokolwiek samemu, czegoś, co wynika z książki, ale nie jest w niej wyklepane czarno na białym. Przecież można napisać zdanie wniosku, własny przekład, cokolwiek. Jak to będzie naiwne, nieciekawe, czy bez sensu to nic się takiego chyba nie stanie - najwyżej będzie trzeba albo swój pomysł obronić, albo powiedzieć: "OK nie mam racji" i albo zmienić, albo trudno - już poszło ;) Niestety ludzie uwielbiają używać argumentu: "Przecież tak jest w książce"...( w domyśle: "Sami mi ją kazaliście przeczytać to się teraz odczepcie").
Człowiek, którego praca jest frankensteinem złożonym na szybko z wikipedii, innych prac półfrankensteinów i książkowych definicji w momencie kiedy nie przepuszcza jej antyplagiat i robi się afera nie powie przecież:
"Tak skopiowałem to na szybko w ciągu ostatniego tygodnia i z braku czasu nie testowałem w necie za 30zł, tylko oddałem - co miałem do stracenia i tak już po terminie by było...". Będzie za to udawał wielkie zdziwienie, mówił jak to brutalny system jest niesprawiedliwy itd... Promotor ma masę prac do sprawdzenia, pełno studentów, którzy przychodzą, albo nie na te seminaria, mało czasu, dużo pracy, stara się być wyrozumiały, sam w końcu kiedyś przechodził coś podobnego i z perspektywy widzi, że nie była to najważniejsza sprawa w jego życiu. Stara się więc problem plagiatu załagodzić, trochę broni studenta, jest lekko sceptycznie nastawiony do systemu... Student skarży się kolegom na niedobry antyplagiat, sprawa roznosi się dalej i dalej... każdy dokłada swoje 3 grosze, że mu to i tamto podkreśliło, "a przecież zmieniał" (miał pisać a nie zmieniać)... Powstaje mit systemu, który jest tak sprawny, że autorom science fiction się o podobnym nie śniło.
ALE
Wszystko wskazuje na to, że jest to stosunkowo proste narzędzie, które wykrywa tylko najbardziej bezmyślne, bezczelne i leniwe kopiowanie ;)
Dla wszystkich, którzy są przerażeni systemem wynik przetestowania 2óch pierwszych rozdziałów mojej pracy, które wielkim dziełem na prawdę nie są ;) (to 0.3 to tytuł ksiązkiw stawiony 3 razy jako op. cit.)
czwartek, 29 kwietnia 2010
RESET HASŁA administratora PRESTASHOP
Krótka informacja, ale przydatna, czyli jak zrestartować hasło w sklepie prestashop mając dostęp do FTP i bazy danych.
1. otwieramy plik: config/settings.inc.php i szukamy w nim definicji stałej "_COOKIE_KEY_" - jest to długi ciąg trudno zrozumiałych znaków ;)
2. w bazie danych wykonujemy następujące zapytanie:
[_COOKIE_KEY_] - to znaleziony w pliku ciąg znaków,
[nowe hasło] - to nowe hasło :),
[naszemail@gmail.com] - to e-mail admina sklepu
ps_ - to domyślny prefix nazw tabel w bazie danych, można go zmienić podczas instalacji, więc zamiast ps_employee, może się zdarzyć: XXXX_employee.
Oczywiście jak nie pamiętamy maila to można go zobaczyć w tabeli XXXX_employee.
1. otwieramy plik: config/settings.inc.php i szukamy w nim definicji stałej "_COOKIE_KEY_" - jest to długi ciąg trudno zrozumiałych znaków ;)
2. w bazie danych wykonujemy następujące zapytanie:
[_COOKIE_KEY_] - to znaleziony w pliku ciąg znaków,
[nowe hasło] - to nowe hasło :),
[naszemail@gmail.com] - to e-mail admina sklepu
ps_ - to domyślny prefix nazw tabel w bazie danych, można go zmienić podczas instalacji, więc zamiast ps_employee, może się zdarzyć: XXXX_employee.
Oczywiście jak nie pamiętamy maila to można go zobaczyć w tabeli XXXX_employee.
wtorek, 20 kwietnia 2010
ODŚWIEŻANIE AJAX I JQUERY
Witam dzisiaj krótki skrypt, robiący to samo, co opisany tutaj, tylko zamiast prototype, wykorzystany jest jQuery. Nie zawsze jest nam na rękę includować prototype ;]
Dane wysyłane postem,ponieważ internet explorer cachuje pobrania GETem.
1000 to liczba milisekund, co jaką treść ma być odświeżana.
link to link do treści
id to id elementu, do którego będzie załadowana treść.
Dane wysyłane postem,ponieważ internet explorer cachuje pobrania GETem.
1000 to liczba milisekund, co jaką treść ma być odświeżana.
link to link do treści
id to id elementu, do którego będzie załadowana treść.
czwartek, 15 kwietnia 2010
NISKA POZYCJA W WP
Dawno, dawno temu moje nieliczne i średnio wykonane strony www zajmowały dobre pozycje w wyszukiwarce WP - zwykle wyższe niż w google. Mówiąc bardzo na oko ze 2 lata temu się to zmieniło i praktycznie nie miały żadnej istotnej pozycji.
W sumie olewałem ten temat, bo z WP nie ma za wiele wejść, a na jakieś szczególne zajmowanie się pozycjonowaniem nie mam czasu, ale nie dawno zupełnie przypadkowo natrafiłem na rozwiązanie problemu:
WP ma swój katalog: katalog.wp.pl i najistotniejszą rzeczą ważącą na pozycji naszej strony jest to, czy jesteśmy do niego dopisani. Dlaczego? bo wpis kosztuje 9zł?
Wszystko jedno - moja skromna stronka jakiś tydzień po dodaniu do katalogu (może z lekkim okładem) z jakiejś dalekiej otchłani wskoczyła na 1 miejsce na frazę: programista freelancer

Na kilka innych fraz ze słowami PHP i programista też jest dobrze, a w dodatku pokazał się różowy znaczek "nowa", który jeszcze bardziej ją wyróżnia. Opis wzięty jest z katalogu, więc mamy nad nim pełną kontrolę - i to wszystko za 9zł, w dodatku płatne SMS ;]
Nic tylko oferować klientom pozycjonowanie w WP za kilka stów/miesiąc ;]
W sumie olewałem ten temat, bo z WP nie ma za wiele wejść, a na jakieś szczególne zajmowanie się pozycjonowaniem nie mam czasu, ale nie dawno zupełnie przypadkowo natrafiłem na rozwiązanie problemu:
WP ma swój katalog: katalog.wp.pl i najistotniejszą rzeczą ważącą na pozycji naszej strony jest to, czy jesteśmy do niego dopisani. Dlaczego? bo wpis kosztuje 9zł?
Wszystko jedno - moja skromna stronka jakiś tydzień po dodaniu do katalogu (może z lekkim okładem) z jakiejś dalekiej otchłani wskoczyła na 1 miejsce na frazę: programista freelancer
Na kilka innych fraz ze słowami PHP i programista też jest dobrze, a w dodatku pokazał się różowy znaczek "nowa", który jeszcze bardziej ją wyróżnia. Opis wzięty jest z katalogu, więc mamy nad nim pełną kontrolę - i to wszystko za 9zł, w dodatku płatne SMS ;]
Nic tylko oferować klientom pozycjonowanie w WP za kilka stów/miesiąc ;]
wtorek, 13 kwietnia 2010
czwartek, 8 kwietnia 2010
Wolne działanie tabeli MySQL
Nie jestem specjalistą od baz danych, więc pewnie dlatego pojawił mi się dzisiaj dziwny problem z tabelą w bazie, której przeglądnięcie pomimo niewielkiej liczby rekordów (200 z hakiem) trwało wieki.
Co się okazuje? MySQL podczas kasowania danych w tabeli nie usuwa ich fizycznie, tylko nadpisuje jakimiś swoimi zerami, nullami, czy czymś podobnym ;)
NIe będę się tutaj rozpisywał, bo nie o to chodzi, ale dane typu tekstowego są przechowywane jako listy linkowane, więc 'pełne' usuwanie byłoby długie, ale za to przez taki śmietnik wyszukiwanie robi się dłuższe, bo wskaźnik chodzi po pustych rekordach. Informację o tym śmietniku MySQL pokazuje nam jako: NADMIAR. Tabela, która mi się zamuliła jest częścią systemu mailingowego i służy jako bufor, wszystkie maile są wrzucane do niej, a skrypt działający w tle sobie je wyciąga, wysyła i po wysłaniu kasuje. W ten sposób zostaje dużo nadmiaru (w moim przypadku ponad 1 MB, czyli sporo jak na tekst). Rozwiązanie okazuje się banalne i oto ono:
Proste, ale jeszcze wczoraj o tym nie wiedziałem - warto zaszyć taką optymalizację w swoich systemach, żeby jakoś okazjonalnie się wykonywała, co może nam czasem oszczędzić kłopotów ;)
AHA ODPOWIEDNIKIEM OPTIMIZE W PostgreSQL JEST VACUUM :)
Co się okazuje? MySQL podczas kasowania danych w tabeli nie usuwa ich fizycznie, tylko nadpisuje jakimiś swoimi zerami, nullami, czy czymś podobnym ;)
NIe będę się tutaj rozpisywał, bo nie o to chodzi, ale dane typu tekstowego są przechowywane jako listy linkowane, więc 'pełne' usuwanie byłoby długie, ale za to przez taki śmietnik wyszukiwanie robi się dłuższe, bo wskaźnik chodzi po pustych rekordach. Informację o tym śmietniku MySQL pokazuje nam jako: NADMIAR. Tabela, która mi się zamuliła jest częścią systemu mailingowego i służy jako bufor, wszystkie maile są wrzucane do niej, a skrypt działający w tle sobie je wyciąga, wysyła i po wysłaniu kasuje. W ten sposób zostaje dużo nadmiaru (w moim przypadku ponad 1 MB, czyli sporo jak na tekst). Rozwiązanie okazuje się banalne i oto ono:
OPTIMIZE TABLE nazwa_tabeli
PO wykonaniu takiego zapytania wszystko zaczęło śmigać jak należy ;)Proste, ale jeszcze wczoraj o tym nie wiedziałem - warto zaszyć taką optymalizację w swoich systemach, żeby jakoś okazjonalnie się wykonywała, co może nam czasem oszczędzić kłopotów ;)
AHA ODPOWIEDNIKIEM OPTIMIZE W PostgreSQL JEST VACUUM :)
wtorek, 6 kwietnia 2010
Czat jak na FACEBOOK
Jednym z ciekawszych narzędzi na portalu facebook.com jest czat. Posiada kilka sympatycznych cech, które czynią go lepszym od tradycyjnych czatów i moim zadaniem są to:
Pytanie co wybrać?
Ja trafiłem na footerchat, który jest banalny jeśli chodzi o instalację - skopiowanie kilku linijek javascriptu, ale niestety tutaj kończą się plusy. Brak polskich znaków (nie tylko polskich:) ), nie zapamiętuje stanu przy przeładowaniu strony, wszystko działa na obcym serwerze, więc jesteśmy ograniczeni w zakresie modyfikacji.
Inne rozwiązanie jakie udało mi się znaleźć jest płatne (cometchat $49 ). Wydaje mi się, że warte swej ceny, szczególnie, że posiada gotowe paczki instalacyjne do popularnych systemów, w tym socialengine - a o to właśnie mi chodziło. Są też gotowce do forów (phpBB, VBuletin)... Jaka zaleta tych gotowców - w przypadku socialengine po instalacji, która polega na skopiowaniu plików, ustawieniu uprawnień i wklejeniu kilku linijek skryptu do strony, dostajemy od razu zintegrowane takie rzeczy jak avatary, czy statusy użytkowników, z czym trzeba by się pewnie troszkę pobawić.
Całość ma nie wiele słów, więc łatwo przetłumaczyć na inny język w pliku konfiguracyjnym, można tworzyć własne skórki, ogólnie wszystko sympatycznie...
poniżej screen z portalu abnormals.org, gdzie instalowałem rozwiązanie:

- PRZYWRACANIE POPRZEDNIEGO STANU PO PRZEŁADOWANIU STRONY
- mały, a jednocześnie umożliwia prowadzenie wielu rozmów jednocześnie i wygodne zarządzanie oknami
- integracja z samym portalem - emotki, przyjaciele, statusy
Pytanie co wybrać?
Ja trafiłem na footerchat, który jest banalny jeśli chodzi o instalację - skopiowanie kilku linijek javascriptu, ale niestety tutaj kończą się plusy. Brak polskich znaków (nie tylko polskich:) ), nie zapamiętuje stanu przy przeładowaniu strony, wszystko działa na obcym serwerze, więc jesteśmy ograniczeni w zakresie modyfikacji.
Inne rozwiązanie jakie udało mi się znaleźć jest płatne (cometchat $49 ). Wydaje mi się, że warte swej ceny, szczególnie, że posiada gotowe paczki instalacyjne do popularnych systemów, w tym socialengine - a o to właśnie mi chodziło. Są też gotowce do forów (phpBB, VBuletin)... Jaka zaleta tych gotowców - w przypadku socialengine po instalacji, która polega na skopiowaniu plików, ustawieniu uprawnień i wklejeniu kilku linijek skryptu do strony, dostajemy od razu zintegrowane takie rzeczy jak avatary, czy statusy użytkowników, z czym trzeba by się pewnie troszkę pobawić.
Całość ma nie wiele słów, więc łatwo przetłumaczyć na inny język w pliku konfiguracyjnym, można tworzyć własne skórki, ogólnie wszystko sympatycznie...
poniżej screen z portalu abnormals.org, gdzie instalowałem rozwiązanie:
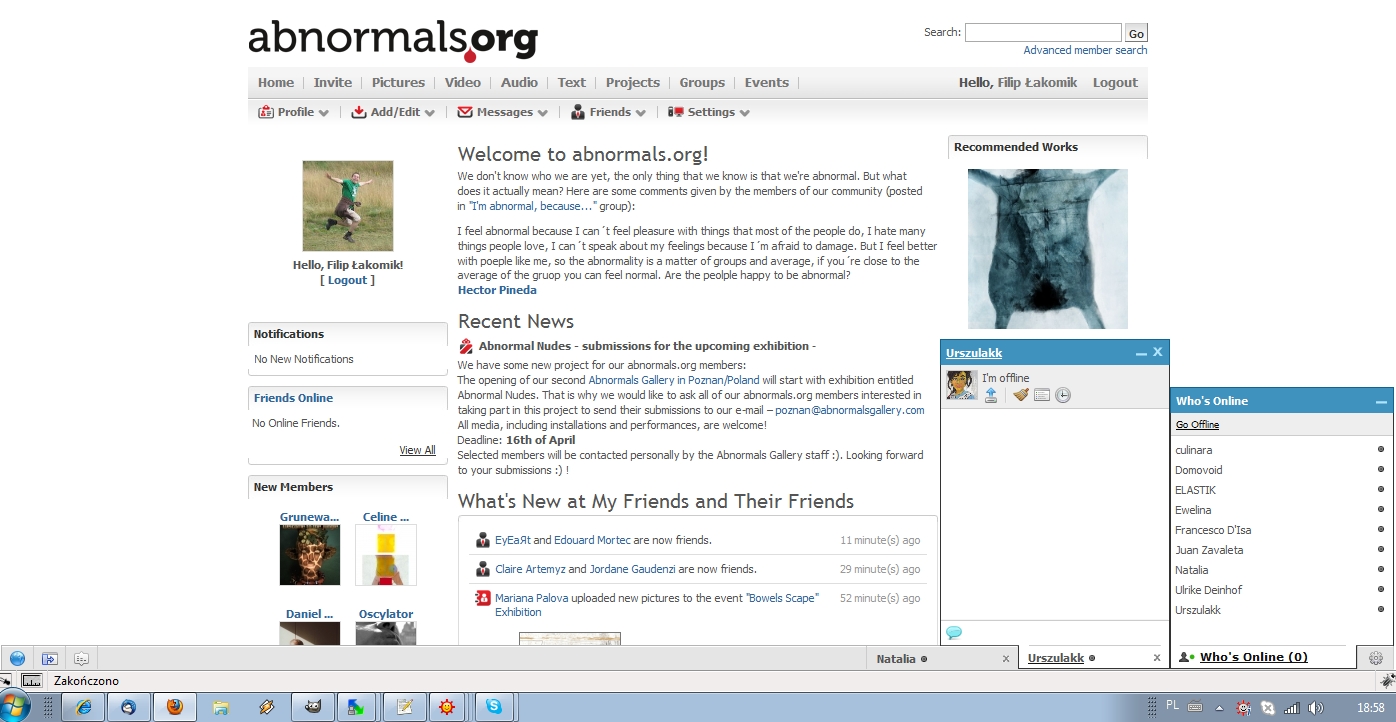
środa, 31 marca 2010
Pseudoklasy CSS, które mogą pozytywnie zaskoczyć
Pewnie każdy pisząc arkusz stylów CSS korzysta z selektora :hover dla linków. Mi rzadko zdarza się wykorzystywać jakieś inne, ale chyba warto o nich pamiętać, tym bardziej, że niektóre działają bardzo sympatycznie i we wszystkich popularnych przeglądarkach.
Będę je tutaj dopisywał, aż uzbiera się kilka, żeby było po co wchodzić;)
zachęcam też do dawania własnych propozycji:
Będę je tutaj dopisywał, aż uzbiera się kilka, żeby było po co wchodzić;)
zachęcam też do dawania własnych propozycji:
- :first-letter - pozwala nadać osobny styl dla pierwszej literki w treści pomiędzy znacznikami, span, div, p itp... przykład
- :first-line - pozwala nadać osobny styl dla pierwszej linijki w treści pomiędzy znacznikami, span, div, p itp... przykład
- :first-child - pozwala się odwołać do pierwszego elementu np listy, lub pierwszej kolumny tabeli.
- :hover - do stosowania nie tylko w linkach, ale np: w wierszach tabeli do podświetlania, lub praktycznie w każdym innym elemencie. Nie wszędzie zadziała (np stare wersje IE), ale zwykle niezadziałanie nie skutkuje problemami ;) oczywiście można się bawić w skrypty onmouseover i onmouseout, ale nie zawsze będziemy chcieli śmiecić...
- :before i :after - niestety nie działają w ie7 i w GC, nie jest to jakaś rewelacja, ale można gdzieś wykorzystać ;)
wtorek, 30 marca 2010
Manualny crop
Wpis troszkę daleko powiązany z tematyka bloga, ale nie mogę się powstrzymać, przed zaprezentowaniem tego co znalazłem w jednym z realizowanych swoich projektów.
Może najpierw fota:
Wyjątkowo kreatywny klient wstawiał zdjęcia produktów na stronę, ale niestety nie posiadał zdjęcia jednego z produktów. Posiadał natomiast katalog, w którym zdjęcie się znajdowało, ale otoczone niepożądanymi literkami :) Sprytny użytkownik przykrył więc litery kartkami papieru i wykonał to arcyzdjęcie :)
... aż mam ochotę przykryć ten wpis dookoła kartkami ;)
Może najpierw fota:

Wyjątkowo kreatywny klient wstawiał zdjęcia produktów na stronę, ale niestety nie posiadał zdjęcia jednego z produktów. Posiadał natomiast katalog, w którym zdjęcie się znajdowało, ale otoczone niepożądanymi literkami :) Sprytny użytkownik przykrył więc litery kartkami papieru i wykonał to arcyzdjęcie :)
... aż mam ochotę przykryć ten wpis dookoła kartkami ;)
niedziela, 28 marca 2010
CACHE IE + AJAX + ODŚWIEŻANIE TREŚCI
Potrzebowałem dzisiaj wyświetlić na stronie aktualny czas, ale nie czas z systemu użytkownika, tylko czas serwera. Myślałem, że sprawa prosta - i jest prosta, ale Internet Explorer postanowił robić figle.
Jeżeli chodzi o samo zastosowanie ajaxa, to nie mam z tym dużego doświadczenia, ale w tym przypadku można sprowadzić problem do kilku linijek wykorzystując bibliotekę prototype.
Kod wygląda tak: Dla wyjaśnienia parametry updatera to:
1. id elementu, którego treść odświeżamy,
2. link do pliku z treścią - w moim przypadku jest tam tylko: echo date("H:i:s");
3. konfiguracja - w tym przypadku: metoda get, częstotliwość co 1s, decay:1 oznacza stałą częstotliwość (wartości >1 oznaczają że im dłuższy czas oczekiwania na odpowiedź tym rzadziej będzie pytał, a mniejsze od 1 odwrotnie szczegóły tutaj).
Wszystko działa pod FireFoxem, ale IE pokazuje ciągle pierwszy wynik, czyli cachuje pierwszy wynik i zegar stoi ;)
ROZWIĄZANIE:
1. zmieniamy GET na POST
2. dopisujemy jakiś parametr do linku, żeby miał co wysłać tym POSTem
Wygląda to tak: Teraz wszystko działa w naszej kochanej przeglądarce.
Może to durne rozwiązanie, ale bardzo krótkie, dlatego uznaję go za dobre, a przede wszystkim skuteczne.
Odświeżanie za pomocą jQuery opisałem tutaj
Jeżeli chodzi o samo zastosowanie ajaxa, to nie mam z tym dużego doświadczenia, ale w tym przypadku można sprowadzić problem do kilku linijek wykorzystując bibliotekę prototype.
Kod wygląda tak: Dla wyjaśnienia parametry updatera to:
1. id elementu, którego treść odświeżamy,
2. link do pliku z treścią - w moim przypadku jest tam tylko: echo date("H:i:s");
3. konfiguracja - w tym przypadku: metoda get, częstotliwość co 1s, decay:1 oznacza stałą częstotliwość (wartości >1 oznaczają że im dłuższy czas oczekiwania na odpowiedź tym rzadziej będzie pytał, a mniejsze od 1 odwrotnie szczegóły tutaj).
Wszystko działa pod FireFoxem, ale IE pokazuje ciągle pierwszy wynik, czyli cachuje pierwszy wynik i zegar stoi ;)
ROZWIĄZANIE:
1. zmieniamy GET na POST
2. dopisujemy jakiś parametr do linku, żeby miał co wysłać tym POSTem
Wygląda to tak: Teraz wszystko działa w naszej kochanej przeglądarce.
Może to durne rozwiązanie, ale bardzo krótkie, dlatego uznaję go za dobre, a przede wszystkim skuteczne.
Odświeżanie za pomocą jQuery opisałem tutaj
sobota, 27 marca 2010
Specjalne czcionki na stronie www
Pierwszy post o skrypcie umożliwiającym wzbogacenie strony www o specjalne czcionki, czyli takie jakich użytkownik może nie mieć zainstalowanych na komputerze.
Niestety nie ma 3-linijkowego rozwiązania problemu ładnych czcionek działającego pod różnymi przeglądarkami.
Popularne rozwiązanie to skrypt: sifr (oparty o flash i js).
Ja używam nieco innego skryptu bazującego na PHP i JS (opis rozwiązania po angielsku).
Dla osoby nie znającej flasha jest na pewno bardziej zrozumiałe, a co za tym idzie łatwiej można go modyfikować, a ponadto zadziała również w przeglądarce bez zainstalowanej wtyczki adobe...
Czego nam potrzeba:
1. plik fonta w formacie ttf (konwersja fonta online)
2. skrypt php, który będzie nam generował napisy ładną czcionką (heading.txt - po pobraniu zmień rozszerzenie na .php)
3. skrypt .js, który podmieni napisy napisane brzydką czcionką, na ładne (replacement.js)
Krótkie wyjaśnienie działania:
heading.php - generuje obrazek w formacie PNG, na którym wypisuje tekst przekazany w parametrze text - po prostu za pomocą funkcji: ImageTTFText wypisuje tekst na obrazek i zwraca tenże obrazek. Dodatkowo ma możliwość włączenia cache, żeby nie generować za każdym razem.
replacement.js - odpowiada za odnalezienie wszystkich napisów które mają być podmienione (np po tagu, czy klasie css) i podmianę tekstu w nich zawartego na wygenerowane obrazki.
Tutaj zwykle ktoś, kto coś słyszał o pozycjonowaniu się przeraża, bo widzi że tekst się nie zaznacza, czyli, że robot tego nie widzi i będzie źle w wyszukiwarkach... ale wystarczy zaglądnąć w źródło strony, żeby zobaczyć, że nic strasznego się nie stało, a wszystkie teksty są na swoim miejscu - całą zabawa odbywa się dopiero po załadowaniu strony za pomocą javascriptu, co raczej robota nie powinno interesować ;]
Dobra teraz szybko co zrobić żeby zadziałało:
1. w sekcji head dokumentu wstawiamy:
2. Domyślnie replacement.js jest napisany tak, że sprawdza najpierw, czy przeglądarka klienta potrafi wyświetlać obrazki (jeśli nie to nie podmienia dla zaoszczędzenia transferu), żeby wykonać to sprawdzenie można wgrać 1-pixelowego png na serwer i podać ścieżkę do niego w 14 linijce. Ja nie widzę większego sensu, żeby to sprawdzać (raczej jak przeglądarka obsługuje JS to da radę wyświetlić obrazek), dlatego w linii 33 zmieniam wartość: var imageLoaded = true; (czyli już sprawdzone).
3. W pliku heading.php w pierwszych linijkach ustawiamy kolor fonta, kolor tła (żeby były ładne krawędzie), rozmiar fonta i oczywiście ścieżkę do pliku z fontem.
I to by było na tyle ;) Działający przykład do pobrania tutaj
Przykłady wykorzystania:
shop.bagastyle.com/
filuteria.pl/
Uwagi:
- polskie znaki w niektórych czcionkach powodują, że napis bywa przesunięty niżej w stosunku do napisu bez polskich znaków np: o kreskę nad "Ś" - można to rozwiązać np dopisując warunek w pliku heading.php, który przesunie w dół teksty bez polskich znaków, albo pobawić się CSSem i wyrównywać obrazki z tekstem do dołu.
Aha i jeszcze jedna rzecz o której zapomniałem wstawianie specjalnych czcionek wymaga jak widać trochę fikołków. Nawet jeśli ktoś powie, że wystarczy wstawić skrypt i już to też nie jest do końca tak, bo nie każdy content jest od razu ładowany na stronie np: treści ładowane ajaxem, albo generowane za pomocą skryptów będą wymagały dogrzebania się odpowiedniego miejsca i dopisania kilku linijek odpalających replacement ponownie... to znowu może w pewnych przypadkach zamulać, albo głupio wyglądać, można coś kombinować z CSSem, ale to znowu moze być potraktowane jako clocking i znowu trzeba coś kombinować... i z powodu głupiej czcionki mamy dużo więcej pracy...
Biorąc pod uwagę powyższe wydaje mi się, że zanim zdecydujemy się na super czcionkę warto przejrzeć listę czcionek, którą kiedyś dawno temu przygotowałem i zastanowić się, czy przypadkiem zastosowanie którejś z nich nie będzie takie straszne.
Na liście jest Helvetica, której nie ma w standardzie w windowsach, ale jak nie ma to system wyświetli ariala, który jest podobny i nic się nie stanie ;) Aha i lista jest według częstotliwości stosowania, którą gdzieś kiedyś znalazłem ;)
Popularne rozwiązanie to skrypt: sifr (oparty o flash i js).
Ja używam nieco innego skryptu bazującego na PHP i JS (opis rozwiązania po angielsku).
Dla osoby nie znającej flasha jest na pewno bardziej zrozumiałe, a co za tym idzie łatwiej można go modyfikować, a ponadto zadziała również w przeglądarce bez zainstalowanej wtyczki adobe...
Czego nam potrzeba:
1. plik fonta w formacie ttf (konwersja fonta online)
2. skrypt php, który będzie nam generował napisy ładną czcionką (heading.txt - po pobraniu zmień rozszerzenie na .php)
3. skrypt .js, który podmieni napisy napisane brzydką czcionką, na ładne (replacement.js)
Krótkie wyjaśnienie działania:
heading.php - generuje obrazek w formacie PNG, na którym wypisuje tekst przekazany w parametrze text - po prostu za pomocą funkcji: ImageTTFText wypisuje tekst na obrazek i zwraca tenże obrazek. Dodatkowo ma możliwość włączenia cache, żeby nie generować za każdym razem.
replacement.js - odpowiada za odnalezienie wszystkich napisów które mają być podmienione (np po tagu, czy klasie css) i podmianę tekstu w nich zawartego na wygenerowane obrazki.
Tutaj zwykle ktoś, kto coś słyszał o pozycjonowaniu się przeraża, bo widzi że tekst się nie zaznacza, czyli, że robot tego nie widzi i będzie źle w wyszukiwarkach... ale wystarczy zaglądnąć w źródło strony, żeby zobaczyć, że nic strasznego się nie stało, a wszystkie teksty są na swoim miejscu - całą zabawa odbywa się dopiero po załadowaniu strony za pomocą javascriptu, co raczej robota nie powinno interesować ;]
Dobra teraz szybko co zrobić żeby zadziałało:
1. w sekcji head dokumentu wstawiamy:
2. Domyślnie replacement.js jest napisany tak, że sprawdza najpierw, czy przeglądarka klienta potrafi wyświetlać obrazki (jeśli nie to nie podmienia dla zaoszczędzenia transferu), żeby wykonać to sprawdzenie można wgrać 1-pixelowego png na serwer i podać ścieżkę do niego w 14 linijce. Ja nie widzę większego sensu, żeby to sprawdzać (raczej jak przeglądarka obsługuje JS to da radę wyświetlić obrazek), dlatego w linii 33 zmieniam wartość: var imageLoaded = true; (czyli już sprawdzone).
3. W pliku heading.php w pierwszych linijkach ustawiamy kolor fonta, kolor tła (żeby były ładne krawędzie), rozmiar fonta i oczywiście ścieżkę do pliku z fontem.
I to by było na tyle ;) Działający przykład do pobrania tutaj
Przykłady wykorzystania:
shop.bagastyle.com/
filuteria.pl/
Uwagi:
- polskie znaki w niektórych czcionkach powodują, że napis bywa przesunięty niżej w stosunku do napisu bez polskich znaków np: o kreskę nad "Ś" - można to rozwiązać np dopisując warunek w pliku heading.php, który przesunie w dół teksty bez polskich znaków, albo pobawić się CSSem i wyrównywać obrazki z tekstem do dołu.
Aha i jeszcze jedna rzecz o której zapomniałem wstawianie specjalnych czcionek wymaga jak widać trochę fikołków. Nawet jeśli ktoś powie, że wystarczy wstawić skrypt i już to też nie jest do końca tak, bo nie każdy content jest od razu ładowany na stronie np: treści ładowane ajaxem, albo generowane za pomocą skryptów będą wymagały dogrzebania się odpowiedniego miejsca i dopisania kilku linijek odpalających replacement ponownie... to znowu może w pewnych przypadkach zamulać, albo głupio wyglądać, można coś kombinować z CSSem, ale to znowu moze być potraktowane jako clocking i znowu trzeba coś kombinować... i z powodu głupiej czcionki mamy dużo więcej pracy...
Biorąc pod uwagę powyższe wydaje mi się, że zanim zdecydujemy się na super czcionkę warto przejrzeć listę czcionek, którą kiedyś dawno temu przygotowałem i zastanowić się, czy przypadkiem zastosowanie którejś z nich nie będzie takie straszne.
Na liście jest Helvetica, której nie ma w standardzie w windowsach, ale jak nie ma to system wyświetli ariala, który jest podobny i nic się nie stanie ;) Aha i lista jest według częstotliwości stosowania, którą gdzieś kiedyś znalazłem ;)
Subskrybuj:
Posty (Atom)
